Regex et Unicode
Accueil Tags Recherche17 Mars 2015
Regex et Unicode
Quels avantages apporte Unicode dans nos regex ?It Would Be So Nice
Afin d’illustrer l’intérêt des caractères Unicode dans les regex, nous allons prendre un problème fréquemment rencontré : comment capturer toutes les lettres et leurs versions accentuées dans une regex ?
Une méthode fréquemment utilisée est la suivante :
[A-Za-z-]+
On capture toutes les lettres majuscules et minuscules, ainsi que le tiret pour les mots composés. Si cette méthode fonctionne plutôt bien pour des identifiants (on pourra alors même l’étendre : [\w-]+), elle est peu fiable en ce qui concerne un language courant, tout particulièrement en français où les accents se font légion.
Voyons comment tenir compte de ces accents…
A New Machine
On peut trouver sur le net quelques (mauvais) exemples de regex cherchant à corriger ce problème :
[a-zA-Z0-9áàâäãåçéèêëíìîïñóòôöõúùûüýÿæœÁÀÂÄÃÅÇÉÈÊËÍÌÎÏÑÓÒÔÖÕÚÙÛÜÝŸÆŒ-]+(vu sur Developpez)[a-zA-Zéèàê]+(vu sur Comment Ça Marche)[a-z0-9àáâãäåçèéêëìíîïðòóôõöùúûüýÿ]+(vu sur Comment Ça Marche)[a-zA-Z0-9ÀÁÂÃÄÅÇÑñÇçÈÉÊËÌÍÎÏÒÓÔÕÖØÙÚÛÜÝàáâãäåçèéêëìíîïðòóôõöøùúûüýÿ]+(vu sur Open Classrooms)- …
Ces solutions sont évidemment loin d’être parfaites. Elles sont verbeuses, longues, difficiles à lire et nécessitent de renseigner l’intégralité des caractères accentués.
What Shall We Do Now?
Un premier pas vers une solution correcte serait d’utiliser les plages de caractères. Vous utilisez fréquemment ces plages sans trop y penser, avec par exemple :
[A-Z]pour capturer les lettres majuscules de A à Z[a-z]pour capturer les lettres minuscules de A à Z[0-9]pour capturer les chiffres de 0 à 9
Mais comment fonctionnent ces plages ?
Quand vous utilisez [A-Z], vous capturez n’importe quel caractère ASCII se trouvant entre le A (équivalent au caractère Unicode \x41), et le Z (équivalent au caractère Unicode \x5a). Si vous regardez la table des caractères Unicode/U0000 (voir ci-dessous), vous remarquez que cela correspond exactement à l’intégralité des majuscules.
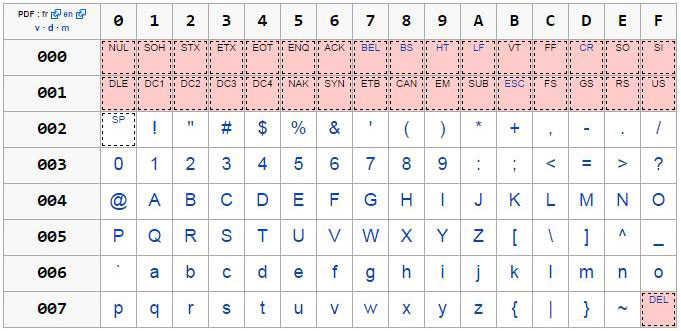
Voici d’autres façons d’écrire cette regex :
[\x41-\x5a]
[\x0041-\x005a]
[\x{41}-\x{5a}]
[\x{0041}-\x{005a}]
De la même manière, vous pouvez très bien choisir de capturer les 4 dernières ligne de la table Unicode/U0080 :
[\xc0-\xff]
[À-ÿ]
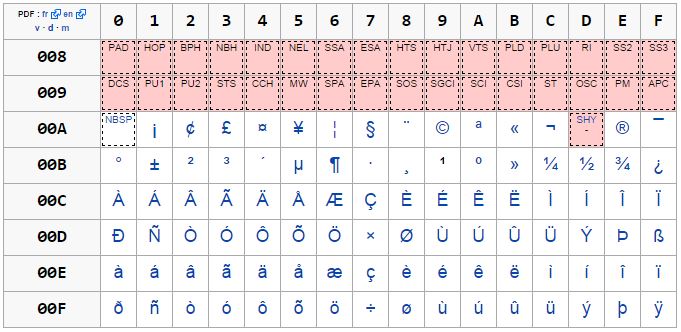
Cette place englobe ainsi tous les caractères entre À et ÿ. Vous noterez que les deux caractères × et ÷ sont aussi inclus dans cette plage. Pour les enlever, vous pouvez à la place utiliser cette regex :
[\xc0-\xd6\xd8-\xf6\xf8-\xff]
[À-ÖØ-öø-ÿ]
…y ajouter les lettres non-accentuées :
[A-Za-zÀ-ÖØ-öø-ÿ]
…et enfin le tiret (à la fin pour éviter tout conflit de plage) et le quantifieur :
[A-Za-zÀ-ÖØ-öø-ÿ-]+
Vous voilà avec une regex (plutôt) courte acceptant bon nombre d’accents ! Le problème n’est malgré tout qu’à moitié résolu. Que faire si une lettre accentuée hors de cette table survient ?
Breathe
La solution ultime réside dans les catégories de caractères Unicode.
Chaque caractère (Unicode) est assigné à une catégorie générale. Ces catégories sont multiples et peuvent être utilisées dans les regex PCRE. En voici quelques unes intéressantes :
\p{L}: les lettres\p{Ll}: les minuscules\p{Lu}: les majuscules\p{Z}: les séparateurs\p{S}: les symboles\p{Sm}: les symboles mathématiques\p{N}: les nombres\p{Nd}: les nombres décimaux\p{P}: la ponctuation
Dans notre cas, il suffira d’utiliser cette regex :
[\p{L}-]+
Simple, court, complet, que demander de plus ?
##Liens Les regex Unicode Table Unicode/U0000 Table Unicode/U0080 Les catégories de caractères Unicode